
从版权的监控、歌曲翻唱的检测、到各种音乐的分类(类型、风格、情调、曲调、年份、时期),乃至于由音乐串流巨人发起的音乐展策战争,音乐识别是目前音乐产业中重要的一环。除了知名全球的Shazam之外,过去二十年来,还有其他无数种的算法也纷纷出笼,各种算法都有其优缺点。本文中,我们将依据所谓的「实例查询(Query-by-example ; QBE)」,带领您概览辨识音频檔中一首或多首歌曲的各种不同方法。
辨识音轨:Shazam 的操作法
首先,我们来介绍鉴别度的概念,所谓鉴别度是指摘录的音频与算法所提取的结果之间相似的程度。举例来说,精确的复制样本能显现出最大的鉴别度,而一首歌曲及其翻唱通常具有中等匹配度,相似度则取决于许多的参数。此种方法是通过高鉴别度的比对算法,将音频中所提取的「指纹」与数据库中歌曲的「指纹」进行比较,达到辨识出所播放乐曲中确切的音轨。
让我们来看看Shazam的典型作法。在大多数情况下,要查询的部份会是音频片段,不会是歌曲的起头部份,有可能会受到噪音的影响,有时甚至会因压缩(数据/力度)或等化而有所改变。要能可靠地进行辨识,音频指纹就必须不会因原始信号的这些变化而受到影响,才能简洁有效的计算,从而优化存储空间和传输速度。
让我们依据Avery Li-Chun Wang的研究,以这首歌来了解Shazam的处理程序。当智能手机的麦克风收录到音频片段,该应用程序就产生歌曲的频谱图 — 表示随时间变化的频率及其强度(音量)。然后,此应用程序会截取最响亮的部份,创建出仅由频率-时间峰值组成所谓的星状图。
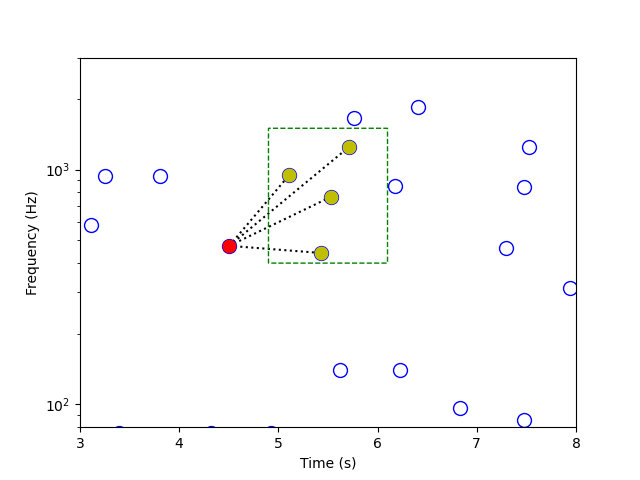
接着,该应用程序会选择一个峰值作为「锚峰」,同时选择一个「目标区域」。将目标区域中的每个峰值与锚峰配对,创建出「哈希值」(即由频率值和峰值之间的时间差所组成的三元组)。将歌曲的星状图与数据库中所有的星状图作比较,哈希值有明显的优势:它具有时间平移不变性(也就是说,没有绝对的时间参考,只有相对的时差);它能更有效地进行数据库的音频指纹匹配;也更不受信号失真的影响。它也更具鉴别度,极短的原始片段也能查询,让应用程序能快速的将结果提供给用户。
Shazam 具有极为明确的辨识能力,即使是假装成现场表演所播放的歌曲也能截取得到:如果该应用程序在演唱会上辨别出其为录音室版本的歌曲,就表示正在播放的就是原始录制的歌曲,直到四分之一音和十六分音符。而相反的,鉴别度恰好也是Shazam最大的弱点:除非这首歌是由完全相同的录音室所录制,否则即使由同一位艺人、以同样的音调与节奏呈现原曲或混音,其算法也无法完全辨识出。因此,就让我们来介绍第二种方法。
辨识歌曲:探究音度(Chroma)
以此种方法辨识,不论是原始的录音室录音、混音或是现场演出的版本,算法都必须识别歌曲,而不是确切的音轨。这就表示音频片段需要包含了特定录音里的某些不变属性。
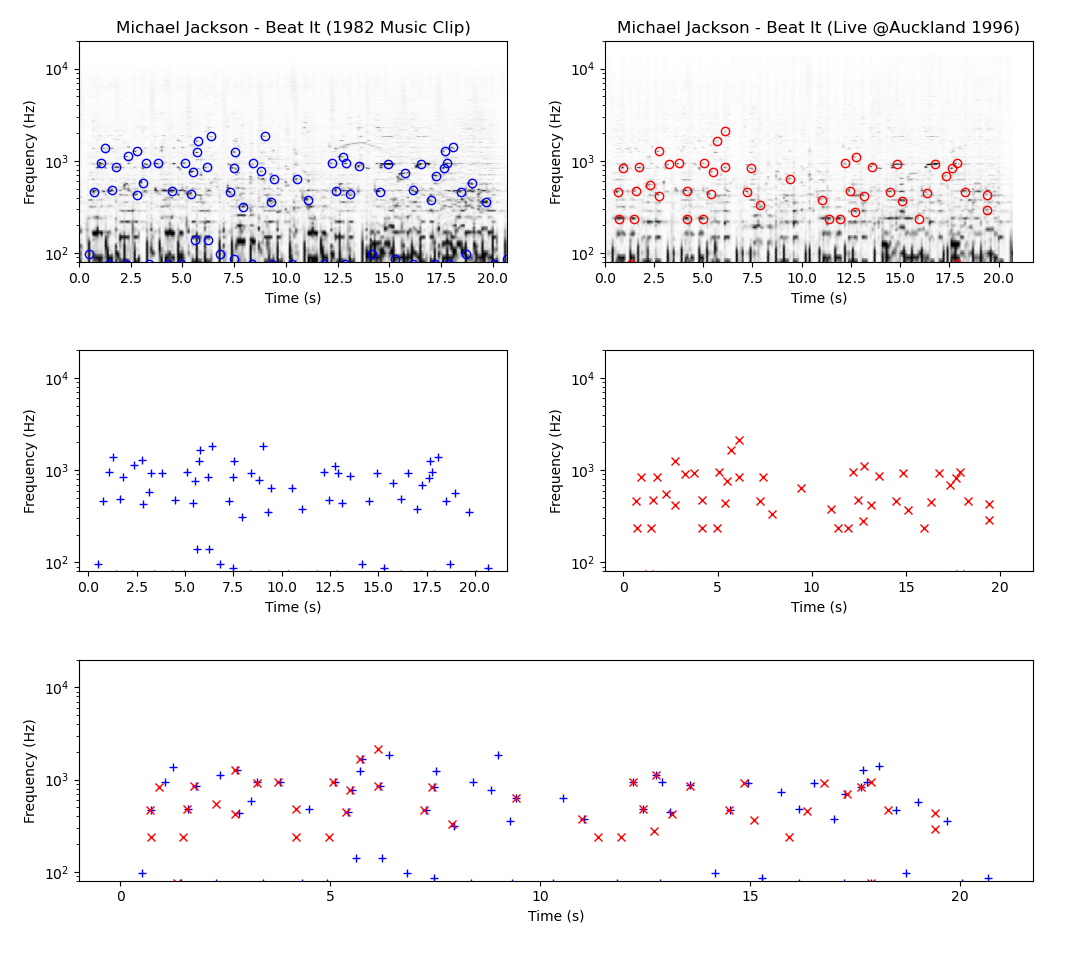
举例来说,此为「Beat It」的原始录音与迈克尔·杰克逊于1996年在奥克兰现场表演的音频峰值指纹比较:如您所见,尽管艺人和曲调相同不变,但两个频谱星状图并非完美匹配。输入音度图(Chromagram):此表示法并非显示作为时间函数的精确频率分解(不仅含音高,且包括音色),而是提取和声进行以及所摘录的旋律特征。换句话说,它描述更多乐曲的形式;假设平均律音程是将音程分类成音阶 — 通常为十二个,代表西方音乐的十二个音调类别(C,C♯,D,D♯,…,B)。
有很多方法可以提取音频文件的音度特征,而这些特征能够利用适当的预处理和后处理技术(频谱、时域和力度)使其更为明显,以形成某些类型的结果(或多或少不让节奏、演出、乐器和其他许多变化受到影响)。
无需比较哈希值,而是将音度特征的整个子序列与数据库的完整音度图进行比较,因此,匹配的过程会比频谱指纹的比对慢得多。简而言之,由于不受音色、节奏和乐器变化的影响,因此,基于音度的方法非常适合检索混音或重新录制的音檔,也可用于检测翻唱,但只适用于中等大小的数据库,当然也无法提供同样精准的音频识别效果。
辨识版本:矩阵(matrix)
最后这一部分,我们将鉴别度的程度降得更低:以此方式进行音频查询时的目标是提取歌曲中任何重新配置的部份,无论与原曲有何不同。让我们以约翰·列侬与塑料小野乐团(John Lennon & The Plastic Ono Band)所演唱的「Imagine」为例,您觉得这个版本如何?从大调到小调,相当简单的调式变化,而歌词的涵义则全然不同 — 这也引出了关于歌曲的界限问题:您认为这是翻唱的歌曲还是一首完全不一样的歌曲?
除了形式(显然是音色)外,翻唱还可能在很多方面与原始构曲不同,像是音调、和声、旋律、节奏特性,甚至是歌词。让我们回头看看第一个例子,比较一下闹翻天男孩(Fall Out Boy)在录音室录制所重新诠释的「Beat It」:
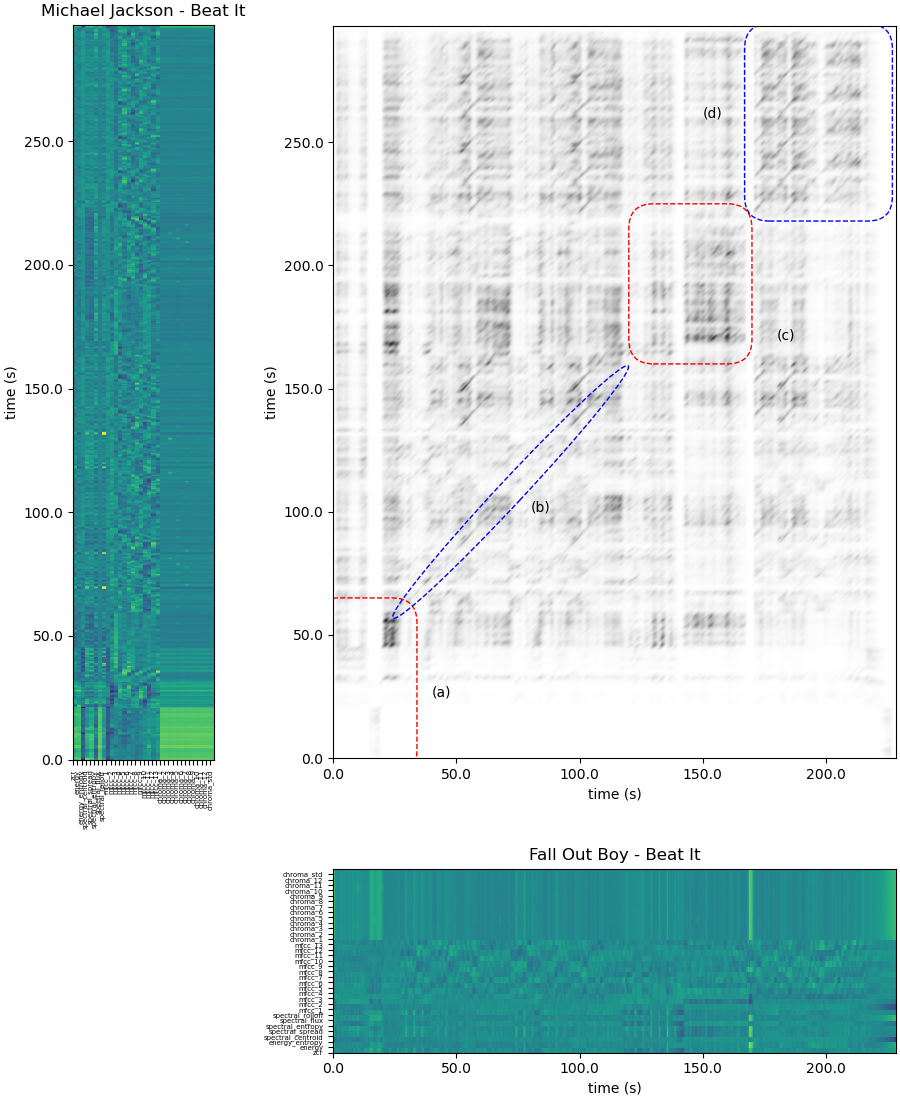
迈克尔·杰克逊(Michael Jackson)所演唱和闹翻天男孩(Fall Out Boy)所翻唱的「Beat It」有着相似的矩阵。
上述如您所见即所谓的相似矩阵,在所查询的曲目和任何音频档间提供成对的相似度:高相似度会以对角线的形式出现。虽然这种类型的矩阵部分是基于音度向量,不过,它也运用到整套指标,包括能量熵、频谱延展度、短时平均过零率和其他等等(您可以参阅此处的详细列表)。让我们仔细研究一下这个特别的相似矩阵 — 在阅览我们的说明时,请随意听听两首歌曲,做个比较。
(a)区没有对角线,表示这两首歌的前奏在结构、声音、和声与旋律方面都大不相同。然而,在(b)区呈现出清楚的对角线,这代表着两者间具有良好的相关性,所比这两个版本在主歌和副歌的部份有十分明显的相似度。在(c)区(即间奏),尽管时间相关性较差,但由于两个版本都有吉他独奏,因此出现小段的对角线。最后,又回复到对角线,也说明了两者在歌曲结尾处(重复副歌)具有相关性。
为了确定两个音频片段是否在音乐方面有所相关,所谓的累积得分矩阵会依据相似矩阵的结果显示出相关部分的长度和质量,并酌予具体扣分,然后将最后的分数从最相似到最不相似进行排名,再以最终的结果用于查询曲目。
可以想象,这类音乐检索机制是一种特别耗费成本的方法。实际上,可以简单地的以「鉴别度越低,复杂度就越高」来概括本文,因为在处理包含了数百万首歌的音乐数据库时,中、低鉴别度的算法仍有许许多多无解的问题。未来,可以将这些互补的方法结合起来,提供更加灵活的体验:想象一下,有个应用程序允许用户在查询曲目时能调整相似度、选择歌曲的特定部分(整个片段或只是一个片段),甚至能显示出他们需要算法去关注的音乐属性。希望如此!
所有的范例均取材于开源Python库中Theodoros Giannakopoulos所开发的音频信号分析数据。
参考资料:
Similarity matrix processing for music structure analysis, by Yu Shiu, Hong Jeong and C.-C. Jay Kuo
Audio content-based music retrieval, by Peter Grosche, Meinard Müller and Joan Serrà
Visualizing music and audio using self-similarity, by Jonathan Foote
Cover song identification with 2D Fourier transform sequences, by Prem Seetharaman and Zafar Rafii